Sumeet Batra
USC Viterbi School of Engineering. ssbatra[at]usc[dot]edu.

I am a 5th year PhD candidate at the University of Southern California advised by Prof. Gaurav Sukhatme in the Robotics Embedded Systems Lab (RESL). My research lies at the intersection of curiosity-driven exploration, perception, and decision-making for robots – focused on how embodied agents can explore, understand, and act in the world in a generalizable manner. I’m particularly interested in how data-driven models can achieve extrapolative generalization: enabling robots to generalize beyond their training data by learning world models and representations that support robust decision-making in novel environments. To this end, I’ve published work on Reinforcement Learning (RL), open-ended learning algorithms such as Quality Diversity (QD) for self-supervised exploration, Generative models such as Diffusion models for robotics, and self-supervised representation learning from RGB inputs for embodied agents.
Previously, I’ve had the privilege of working with the Autonomous Vehicles team at NVIDIA as a research scientist intern in 2022 and 2023 on Reinforcement Learning for autonomous driving and Diffusion models for scenario generation. Before that, I was an intern at the National Institute of Standards and Technology (NIST), where I worked on Generative Adversarial Networks (GANs).
news
| Jul 15, 2024 | Invited to a panel with The Walking Dead showrunner Glen Mazzara to discuss the influence of AI and robotics on pop culture. |
|---|---|
| May 01, 2023 | Joined NVIDIA as a Research Scientist Intern in the Autonomous Vehicles team, working on Diffusion models for scenario generation. |
| May 10, 2022 | Joined NVIDIA as a Research Scientist Intern in the Autonomous Vehicles team, working on Reinforcement Learning for autonomous driving. |
selected publications
- arXiv
 Zero-Shot Visual Generalization in Robot ManipulationarXiv preprint arXiv:2505.11719, 2025
Zero-Shot Visual Generalization in Robot ManipulationarXiv preprint arXiv:2505.11719, 2025 - ICML
 Zero-Shot Generalization of Vision-Based RL Without Data AugmentationInternational Conference on Machine Learning, 2025
Zero-Shot Generalization of Vision-Based RL Without Data AugmentationInternational Conference on Machine Learning, 2025 - NeurIPS
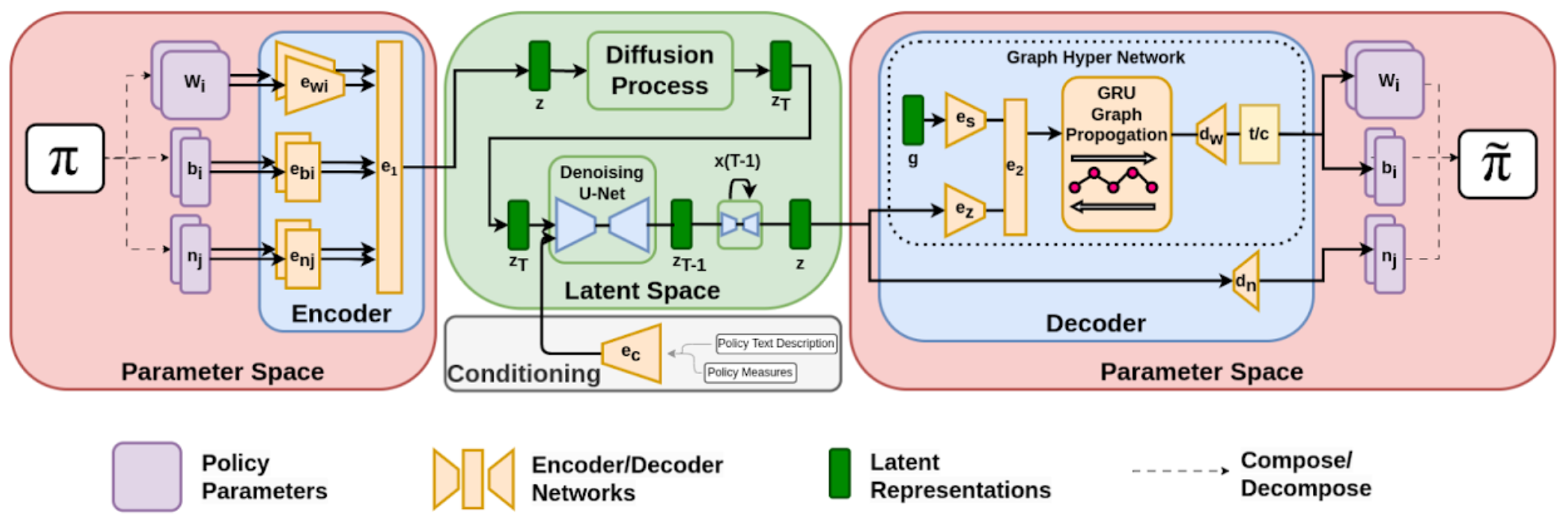 Generating Behaviorally Diverse Policies with Latent Diffusion ModelsAdvances in Neural Information Processing Systems, 2023
Generating Behaviorally Diverse Policies with Latent Diffusion ModelsAdvances in Neural Information Processing Systems, 2023 - GECCO
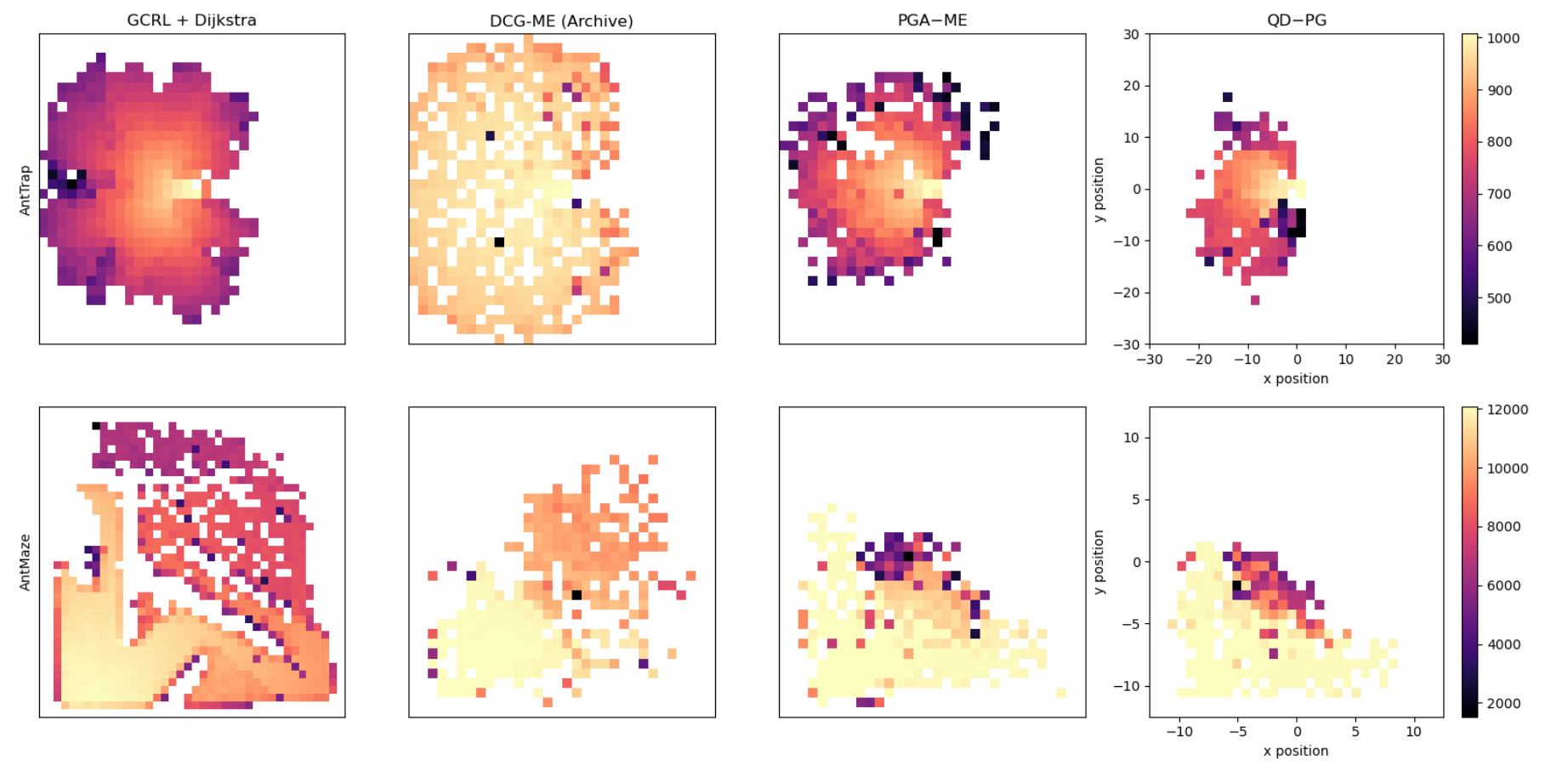 Quality Diversity for Robot Learning: Limitations and Future DirectionsProceedings of the Genetic and Evolutionary Computation Conference Companion, 2024
Quality Diversity for Robot Learning: Limitations and Future DirectionsProceedings of the Genetic and Evolutionary Computation Conference Companion, 2024 - ICRA
 Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning2024 IEEE International Conference on Robotics and Automation (ICRA), 2024 - CoRL
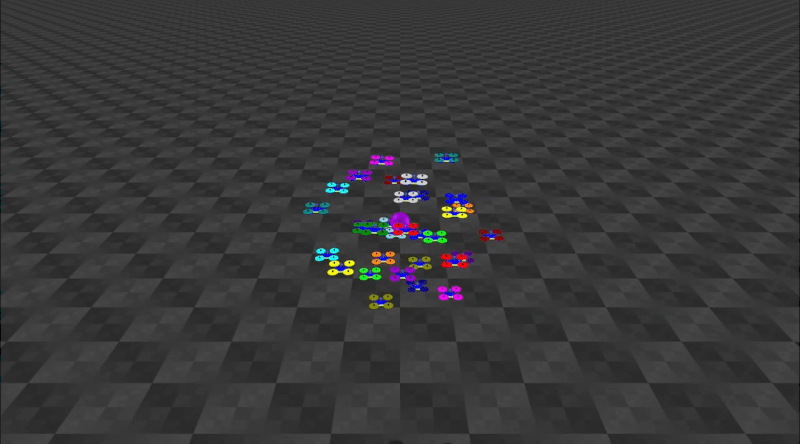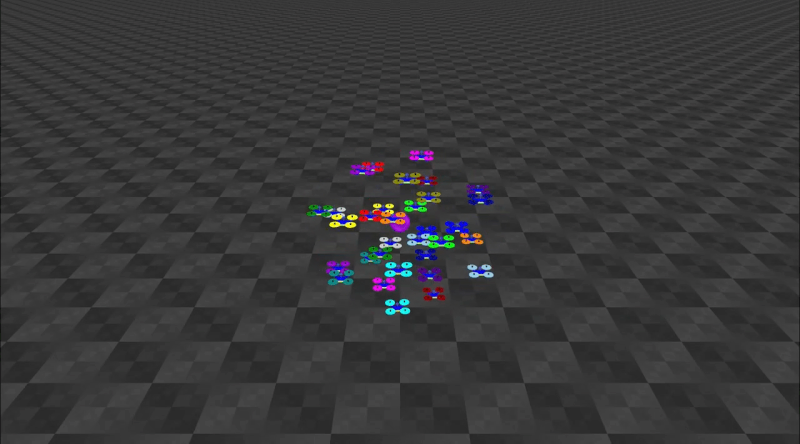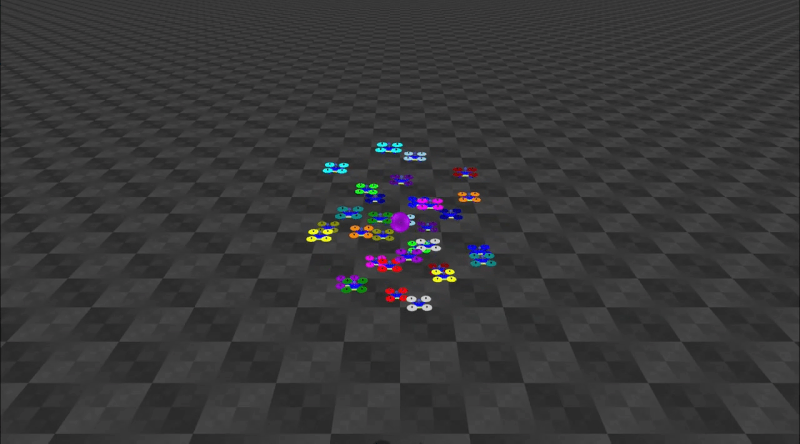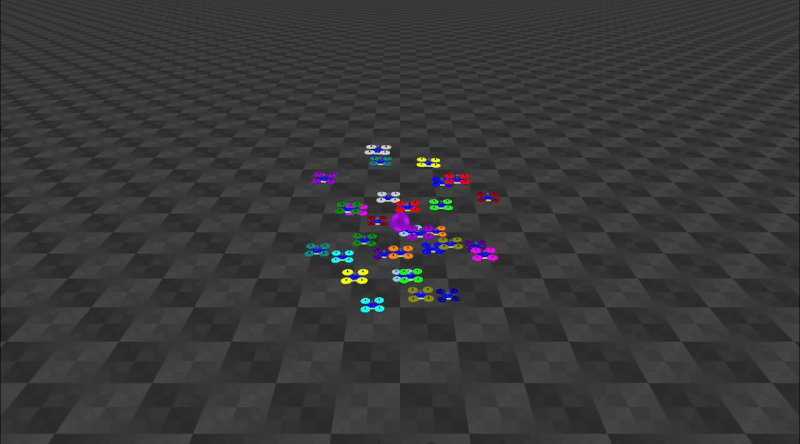 Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement LearningConference on Robot Learning, 2022
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement LearningConference on Robot Learning, 2022
